Monster_Hunter_Frontier CS 175: Project in AI (in Minecraft)
Project Summary
Our project design is based on a mod of Minecraft, monster hunter frontier, where an agent can learn how to kill a monster efficiently by Q-learning in that environment. We set up a 40x40 battleground for an agent and a monster to fight each other. The agent will be given a special melee weapon at the beginning of the game, and the agent will attack the monster automatically whenever the monster is within the agent’s attack range. The agent will be granted a certain amount of reward when successfully hitting the monster so that the agent can learn from some sequence of actions. Also, the agent will granted a negative reward when get hit by the monster to form better learning. Our goal is to let the agent make the best action while the monster is alive, such as moving to a certain place to doge attack or moving towards the monster and attack it.
Approach
The algorithm we use is Q-learning. Q-learning can learn a policy that tells the agent which action can maximum the reward in a given state. The update function for Q-learning in time t is Q_new = (1-learning_rate) * Q_old + learning_rate * (reward + discount_factor * Q_optimal). In our project, we use Q-learning to update the Q-table and then choose the best action from Q-table. If there are multiple actions give the same Q value, we will choose one of them randomly. Using Q-table, our agent will have an optimal policy to handle different circumstances.
Other reason that we use Q-learning because we only have a few states. Our states are the combination of two features, the distance between agent and monster and a value representing whether the monster is facing the agent or not. The facing is a Boolean value, true if monster facing the agent, false otherwise. We apply this feature to make sure the agent is always facing the monster. For the distance parameter, we simplify it to three types, “close” distance less than 5 blocks, “medium” distance larger than 5 and less than 15 blocks, and “far” distance larger than 15. There are two reasons why we simplify the distance in this way. First, the distance is a real number, if we directly use it as the state without any modifications, the number of states will be very large and the agent may not go to any same state again. Secondly, a little amount changing of distance does affect the agent, for example, the Q-value for 13 and 14 distance are almost the same. Therefore, we only have six states in total.
The actions that the agent has are movements such as front, back, left, and right. The attack and turning of the agent are hardcoded in the function. The agent is always facing the monster, and when the distance between the agent and the monster is less than 5, the agent will attack.
The reward function takes the agent health point and monster health point as input. If the agent loses health point or dies, it will deduct reward. If the monster loses health point, the agent will get a positive reward. When either agent or monster die, the mission will end. If no one gets damaged, the reward will be -1.
Evaluation
Quantitative evaluation
We use the monster total damage for the quantitative evaluation. The goal of our project is let the agent learns how to kill the monster efficiently, so if the agent does learn the policy of killing the monster, it will try to damage the monster as much as possible. Therefore, the damage for each trial is a good parameter to estimate how good the agent performs.
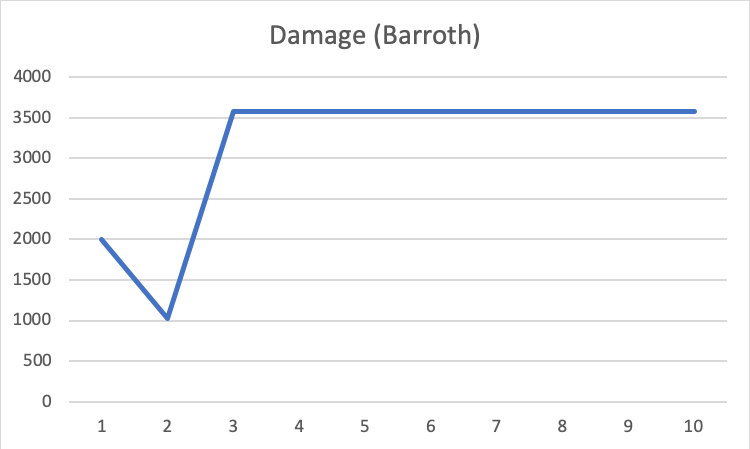
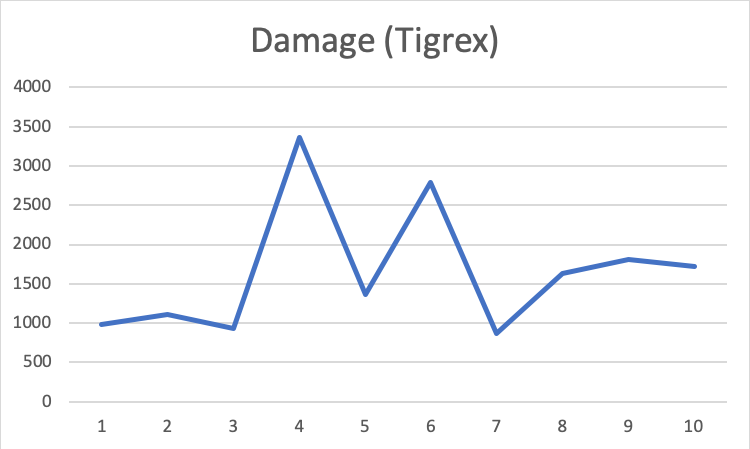
When agent combat with Barroth. With only a few trains, it learns how to kill the monster. Then when it deals with Tigrex, which is another monster and harder to fight, the result is worse. However, after some overlayers, the agent begins to learn how to fight. The above graph has shown that the average damage of the last three trials are better than the first three trials, indicating that the agent does learn how to fight with the monster by Q-learning.
Qualitative evaluation
For qualitative evaluation, we use the final score of each trial. The final score is the cumulated reward that the agent gets in a trial. It shows how well the agent can kill the monster. The final score will be decreased if the agent is hit by the monster or it takes too long to kill the monster. It will ensure that the agent really knows the best way to handle the monster, like dodging monster’s attack.
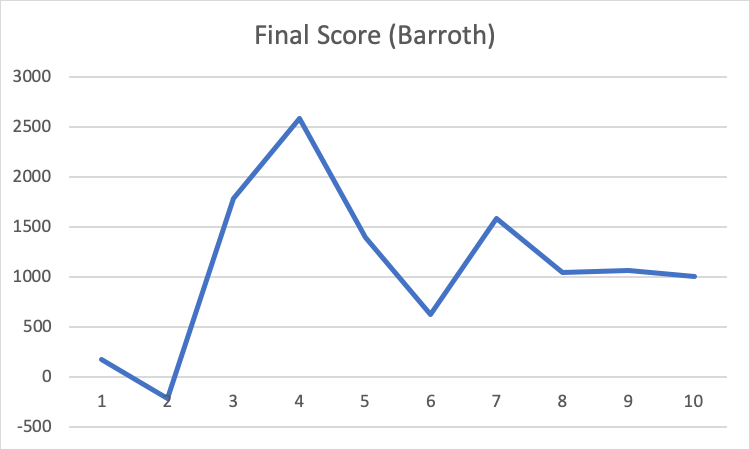
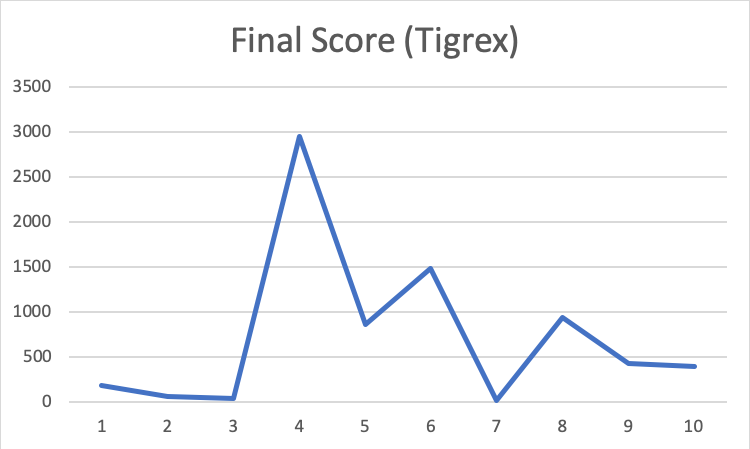
The above two graphs are very similar. Comparing the first few trials and the last few one, the score does improve, but it does not seem like it finds the best way to fight. The score is fluctuating.
Video

Remaining Goals and Challenges
First, our agent knows how to kill the monster, but can’t avoid damage from the monster and it takes a long time to kill the monster, so we want to let it learn a way to maximize the final score. Secondly, in this prototype, we only use the Q-learning, so we may try other methods in the next few weeks, like gradient policy. At last, we will change our states, since they are quite simple, so in many different circumstances; they may be represented by the same state. Also, we want to add more features. Currently, we only have two features to represent the circumstance, which is hard for the agent to predict the next action of the monster precisely. We will not change the hard coding part since we want the agent to always face the monster and attack when it is close to the monster. Learning those skills waste a lot of time, so hard coding this part is better, and it does improve the final score. Our ultimate goal is let the agent know how to kill the monster without getting damage and with least amount of time, which means the agents need to predict monster’s next action and choose the best action to do. Therefore, locating the monster and sequence of actions that make the agent get close to it are essential.
Resources Used
Reference code:
UCI CS175 2019 spring assignment2
Reference article:
https://medium.com/emergent-future/simple-reinforcement-learning-with-tensorflow-part-0-q-learning-with-tables-and-neural-networks-d195264329d0
https://medium.com/@m.alzantot/deep-reinforcement-learning-demysitifed-episode-2-policy-iteration-value-iteration-and-q-978f9e89ddaa