Monster_Hunter_Frontier CS 175: Project in AI (in Minecraft)
Video

Project Summary
Our project design is to let an agent can learn how to kill a monster efficiently by Q-learning in a given environment. We set up a 40x40 battleground for an agent and a monster to fight each other. The agent will be given a special melee weapon at the beginning of the game, and the agent will attack the monster automatically whenever the monster is within the agent’s attack range. Every successful hit will grant the agent some reward, killing the monster will grant a large amount of reward so that the agent can learn from some sequences of actions. Also, if the agent gets hit or dies, the agent will be granted a negative reward respectively. Our goal is to let the agent make the best action while fighting the monster, such as moving to a certain place to doge attack or moving towards the monster and attack it. In this problem setup, AI/ML algorithm is needed. Since the monster is consistently making actions under some certain patterns. The AI/ML algorithms can let agent adapt to that pattern very quickly and output the best actions for the agent.
The challenge for our design was defining the state for our agent. The Malmo only provided a few parameters of the monster, and those data were raw data. When fighting with the monster, our agent had a lot of factors to consider, we had to preprocess those raw data into some useful data, such as distance to the monster, facing direction, so the agent could learn how to dodge the attack easily. When taking all of those factors into the learning process, it becomes complicated.
Approach
The algorithm we use is Q-learning. Q-learning can learn a policy that tells the agent which action can maximum the reward in a given state. The update function for Q-learning in time t is
Q_new = (1-learning_rate) * Q_old + learning_rate * (reward + discount_factor * Q_optimal).

In our project, we use Q-learning to update the Q-table and then choose the best action from Q-table. If there are multiple actions give the same Q value, we will choose one of them randomly. Using Q-table, our agent will have an optimal policy to handle different circumstances.
Another reason that we use Q-learning because we only have a few states. Our states are the combination of three features, the distance between the agent and the monster, does the monster facing the agent and the speed of the monster. The monster facing is a Boolean value, true if the monster facing the agent, false otherwise. This feature let the agent avoid let the monster facing us. For the distance parameter, we simplify the real distance into different categories, if the distance is less than three, define this circumstance into category one, if the distance between three to six, we define this circumstance into category two, if distance between six to nine, it is category three, and so on. There are two reasons to simplify the distance. First, distance is a real number, if we directly use it as the state without any modifications, the number of states will be very large and the agent may not go to the state again. Second, a little amount changing of distance does affect the agent, for example, the Q-value for 10 and 11 distance are almost the same. Therefore, we only have six states in total. The last feature is the monster’s speed, this tells the agent that the monster is moving or not, if it is moving, then in the agent’s view, the monster might be attacking. This feature helps the agent learn when to dodge.
The actions that the agent has are move front, back, left, right. The attack and turn are hardcoded in the function. The agent is always facing the monster and always attack.
The reward function takes the agent health point and monster health point as input. If agent loss health point or die, it will deduct reward. If the monster loss health point, the agent will get a positive reward. When either agent or monster die, the mission will end. If no one gets damage, the reward will be -3, it encourages the agent to kill the monster as fast as possible.
Evaluation
Damage
We use the monster total damage for the quantitative evaluation. The goal of our project is let the agent learns how to kill the monster, so if the agent does learn the policy of killing the monster, it will try to damage the monster as much as possible. Therefore, the damage for each trial is a good parameter to estimate how good the agent performs.
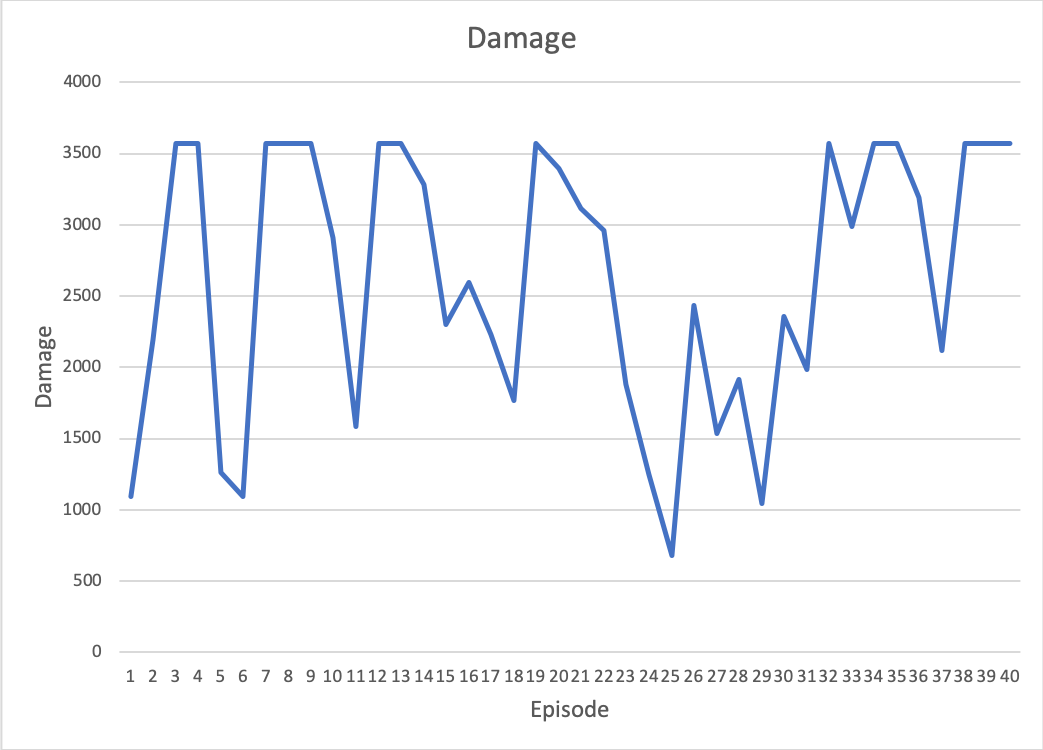
The health of the monster is around 3500, so the agent does try to kill the monster. However, it is hard to kill the monster every time, for the monster is very active and power, if the agent makes a mistake, it will get a lot of damage. Around 20 to 30 episodes, there a valley. We think the problem is that the agent updates the policy in some special case, and it affects the original policy.
Score
The score is a very important source to evaluate the agent how good they learn to kill the monster.
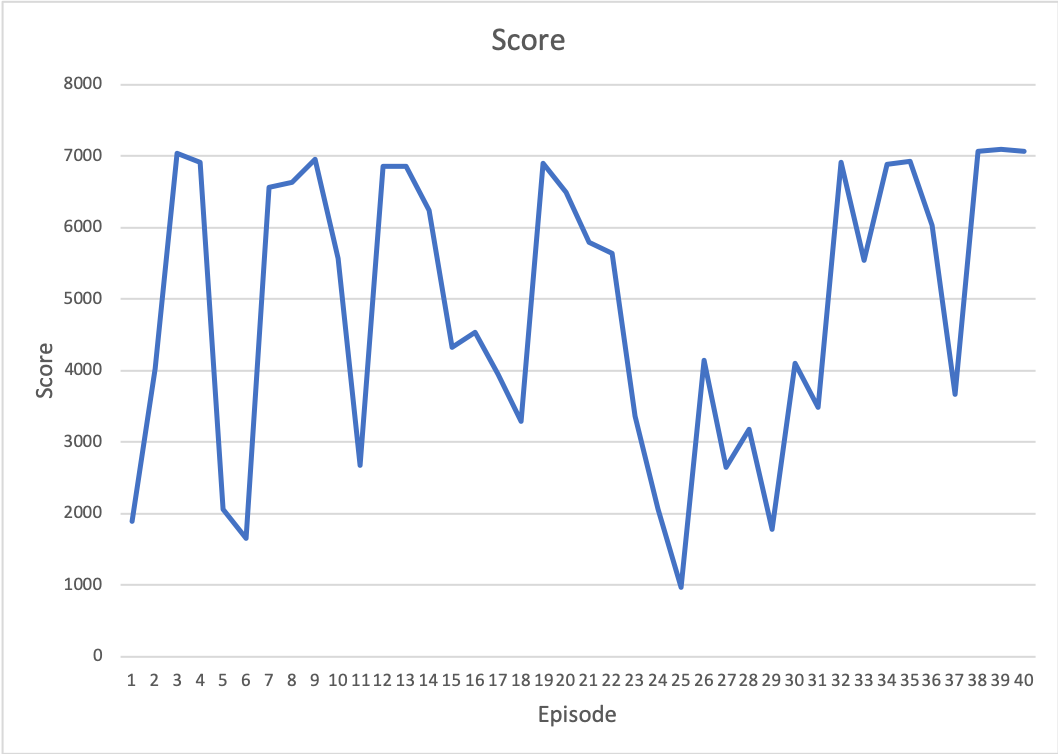
The score and damage graph are similar, for the damage affect the score heavily.
The movement of the monster is very hard to predict, which can be a reason why there is a valley around 36-39 rounds. Overall, the score of the agent stays around 7000 after learning. Therefore the agent does learn its goal of killing the monster.
Run time
Our ultimate goal is to let the agent kill the monster as fast as possible. Therefore, the run time is also important.
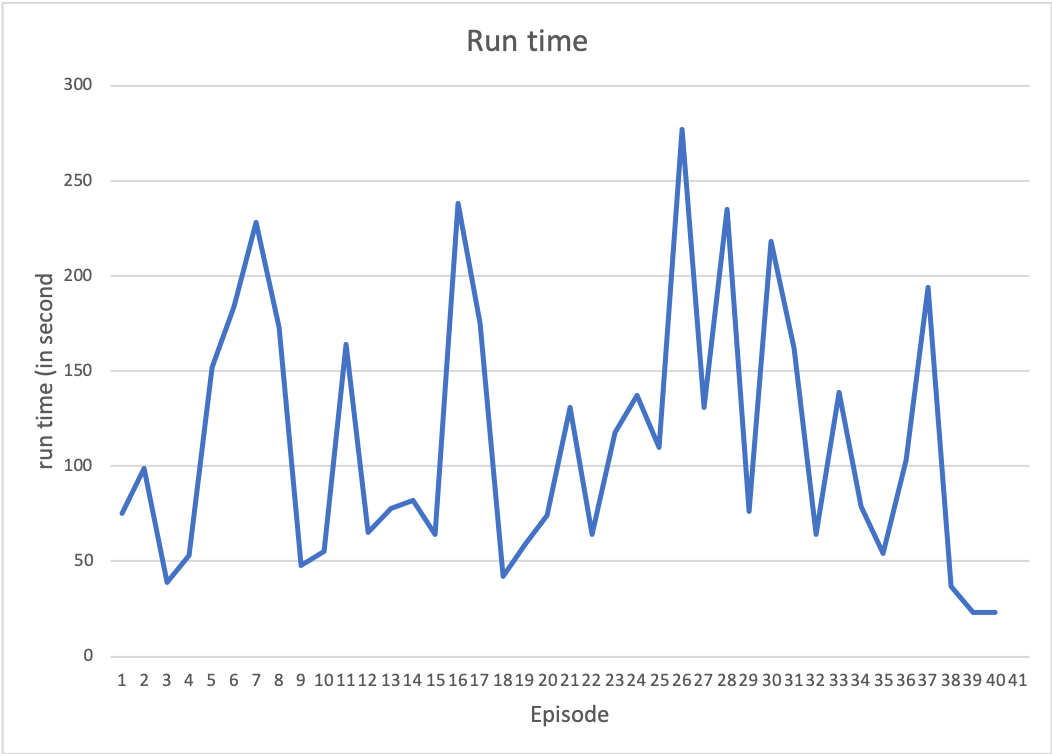
Comparing the run time and the above two graphs, we can see that when the scores are low, the run time is also longer. If the agent requires longer time, it usually in some new circumstances, so it takes some random action and wastes time. Because the agent does not know how to do, it is easily got kill be the monster and cause a lower score.
The graph above shows that there is a decreasing trend on the rounds 29-41. Even though at some trials the running time is not always decreasing, again the monster’s movement is complicated and hard to predict, so it is possible to have bizarre result in some trial. In addition, the score has an increasing trend line. Therefore, the decreasing trend line in this graph indicates that the agent is learning to accomplish our goal of killing the monster as soon as possible.
Reference
Reference code:
UCI CS175 2019 spring assignment2
Reference article:
https://medium.com/emergent-future/simple-reinforcement-learning-with-tensorflow-part-0-q-learning-with-tables-and-neural-networks-d195264329d0
https://medium.com/@m.alzantot/deep-reinforcement-learning-demysitifed-episode-2-policy-iteration-value-iteration-and-q-978f9e89ddaa